Twitterbots & Textgenerierung
Tag 1: Vorstellung, Organisatorisches, Textgenerierung
Esther Seyffarth
29.02.-04.03.2016
Heute:
- Vorstellung (des Seminars und der Teilnehmenden)
- Organisatorisches
- Theoretischer Überblick über Aspekte der Textgenerierung
Vorstellung
- Warum bin ich hier?
- Warum seid ihr hier?
Über mich
- BITTE NICHT SIEZEN!
- Masterstudentin InfoWiss im 4. Semester
- Bachelor in Anglistik und Computerlinguistik von der Ruhr-Uni Bochum
- Interesse an Twitterbots seit ca. 2011, Programmierung eigener Bots seit Januar 2015
- Mein erster Twitterbot: @parsextoto
Über euch
- Wer war schon beim Twitterbot-Workshop im August 2015?
- Wer hat schon mal tweepy benutzt, z.B. in der Bachelorarbeit oder in InfoWiss-Seminaren?
- Wer kennt schon einen oder mehrere Twitterbots?
- Wer ist hier, ohne die Credit Points zu brauchen?
- Wer hat schon mal etwas anderes studiert als Informationswissenschaft?
Über dieses Seminar
- Ziel: Interesse, Begeisterung und Know-How über Twitterbots vermitteln
- Programmierübung für immer wiederkehrende Python-Probleme
- Überblick über den Themenbereich der Textgenerierung (Natural Language Generation)
- Kreative Arbeit
- Fun Fact: Twitterbots können gelegentlich zu Jobangeboten führen!
Organisatorisches
- Veranstaltungsort: 23.21.04.87
- Beginn am 29.02., 01.03., 02.03. und 04.03.: 10:00 Uhr
- Ende: Je nach Produktivität, Klärungsbedarf, Dauer der Pause, ... jeweils ca. 16:00-17:00 Uhr
- Achtung: Am 03.03. findet kein Unterricht statt! Dieser Tag ist zur Bearbeitung der Projekte und Vorbereitung der Referate gedacht.
Eure Leistung
- Mitarbeit auch im theoretischen Teil des Seminars (keine Angst, das wird nur heute sein)
- Erstellen eines eigenen Twitterbots - gerne in Zweiergruppen, zum Schluss soll aber ein Bot pro Person gebaut werden
- Möglichkeiten zum Erhalten des BN:
- Kurzreferat über den Bot (10-15 Minuten) plus 2-seitige schriftliche Ausarbeitung
- Im Notfall: Kein Referat, 4-seitige schriftliche Ausarbeitung
- Je unfertiger der Bot, desto länger das Referat
Bestandteile des Referats und der Ausarbeitung
- Idee - wie ist der Plan für den Bot entstanden?
- Inspirationen - habt ihr euch an anderen existierenden Bots orientiert?
- Wahl der Korpora und Pakete erläutern
- Quellcode zeigen und Schritt für Schritt erklären
- Live-Demo
- Bei unfertigen Bots: Beschreibung von und Reflektion über aufgetretene Probleme, mögliche Lösungsansätze
Textgenerierung
Warum Textgenerierung?
- Welche Gründe fallen euch ein, Texte automatisch zu generieren?
- Welche konkreten Anwendungsfälle kennt ihr?
Gründe für Textgenerierung
- Generieren ist günstiger als schreiben
- Die Maschine schreibt besser als der Mensch?
- Riesige Datenverarbeitung, die ein Mensch gar nicht inhaltlich auf einmal erfassen könnte
- Direkte Interaktion zwischen Nutzer und Gerät (z.B. beim Handy oder Navi)
- Informationsvermittlung individualisieren, z.B. Börsenberichte, Wettervorhersage, Sportberichte...
Konkrete Anwendungsfälle
- Wetterberichte
- Berichte über regionale Fußballspiele
- Softporn-E-Books auf Amazon
- Produktbeschreibungen in Onlineshops
- Automatische Zusammenfassungen
- Sprachausgabe bei Handys, Navis, Telefonbandansagen...
- Chatbots, automatische Assistenten
- Automatische Bildbeschreibungen
- Kunst (Bots, Novel Generation, ...)
- Spam, Fake-Profile auf Dating-Plattformen
- ...
Ist das Informationswissenschaft?
Wie wirken generierte Texte? (Aufgabe)
Theorie der Textgenerierung
- Reiter, E., & Dale, R. (1997). Building applied natural language generation systems. Natural Language Engineering, 3(01), 57-87. [PDF]
- Martin, J. H., & Jurafsky, D. (2000). Speech and language processing. International Edition [Table of Contents]
- Reiter, E., Sripada, S., Hunter, J., Yu, J., & Davy, I. (2005). Choosing words in computer-generated weather forecasts. Artificial Intelligence, 167(1), 137-169. [PDF]
- Dale, R., Geldof, S., & Prost, J. P. (2005). Using natural language generation in automatic route. Journal of Research and practice in Information Technology, 37(1), 89. [PDF]
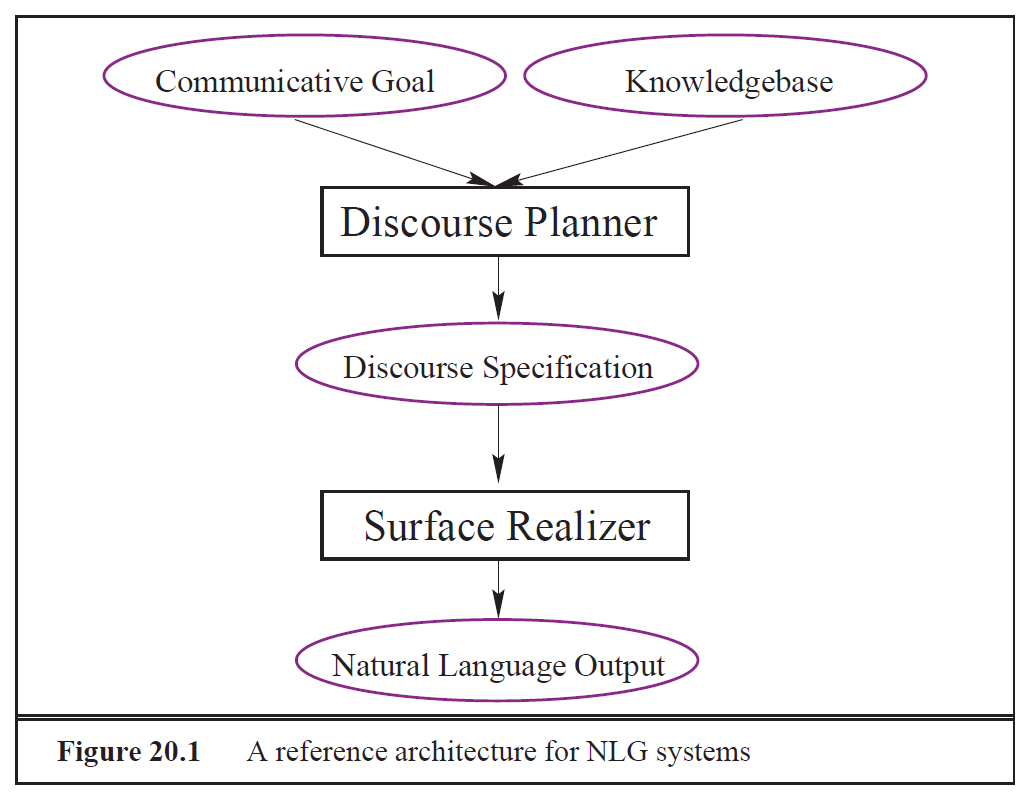
Building Applied Natural Language Generation Systems
In this article, we give an overview of Natural Language Generation (NLG) from an applied system-building perspective. The article includes a discussion of when NLG techniques should be used; suggestions for carrying out requirements analyses; and a description of the basic NLG tasks of content determination, discourse planning, sentence aggregation, lexicalization, referring expression generation, and linguistic realisation.
Ziel von NLG-Systemen
- Informationen auf verständliche Weise für bestimmte Nutzergruppen aufbereiten
- Übersetzung von Datenbanken, Tabellen, Sensordaten, logischen Formeln in natürliche Sprache
- Spezieller Fokus auf Nicht-Experten, die mit den Rohdaten wenig anfangen können
- NLG als Unterstützung für menschliche Autoren (vgl. Übersetzungstools)
Gründe für/gegen Textgenerierung
- Oft können Daten graphisch besser erfasst werden als in Textform
- Bei kritischen Texten ist es möglicherweise angebracht, menschliche Autoren einzusetzen
- Generierungssysteme sorgen möglicherweise für eine höhere Genauigkeit/Zuverlässigkeit, weil Computer keine Flüchtigkeitsfehler machen
- Weitere Faktoren: Art der Informationen, gewünschte Variationen im Text, Menge, rechtliche Kriterien, "distribution constraints" (... im Jahr 1997)
Entwurf von NLG-Systemen
- Iterative Herangehensweise, Prototyping
- Initial Corpus: Menge von Datensätzen und dazugehörigen Texten, die als Basis dienen
- Target Corpus: Überarbeitete Version, bei der z.B. Abweichungen, Konflikte oder Fehler entfernt wurden
Aufgaben eines NLG-Systems
- Content Determination: Welche Daten sollen versprachlicht werden?
- Discourse Planning: In welcher (inhaltlichen) Struktur?
- Sentence Aggregation: Welche Messages sollen zu Sätzen zusammengeführt werden?
- Lexicalization: Durch welche Wörter oder Phrasen sollen die Informationen ausgedrückt werden?
- Referring Expression Generation: Wie soll auf Entitäten referiert werden?
- Linguistic Realization: Welche morphologischen und syntaktischen Constraints gelten?
Beispiel: Zugauskunft
Text aus dem Target Corpus:
Content Determination: Auswahl von Messages

Content Determination
- Um diese Aufgabe zu vereinfachen, wird oft ein User Model verwendet: Welche Messages wichtig sind, hängt vor allem davon ab, was der User bereits weiß und welches Ziel er oder sie hat; Stichwort Pertinenz
- Außerdem hängt die Auswahl der Messages stark von Einzelheiten der jeweiligen Anwendung ab
- Allgemeine Aufgabe: Informationen filtern, zusammenfassen, Inputdaten verarbeiten und nützlichen Output dazu produzieren
Discourse Planning: Strukturierung der Messages
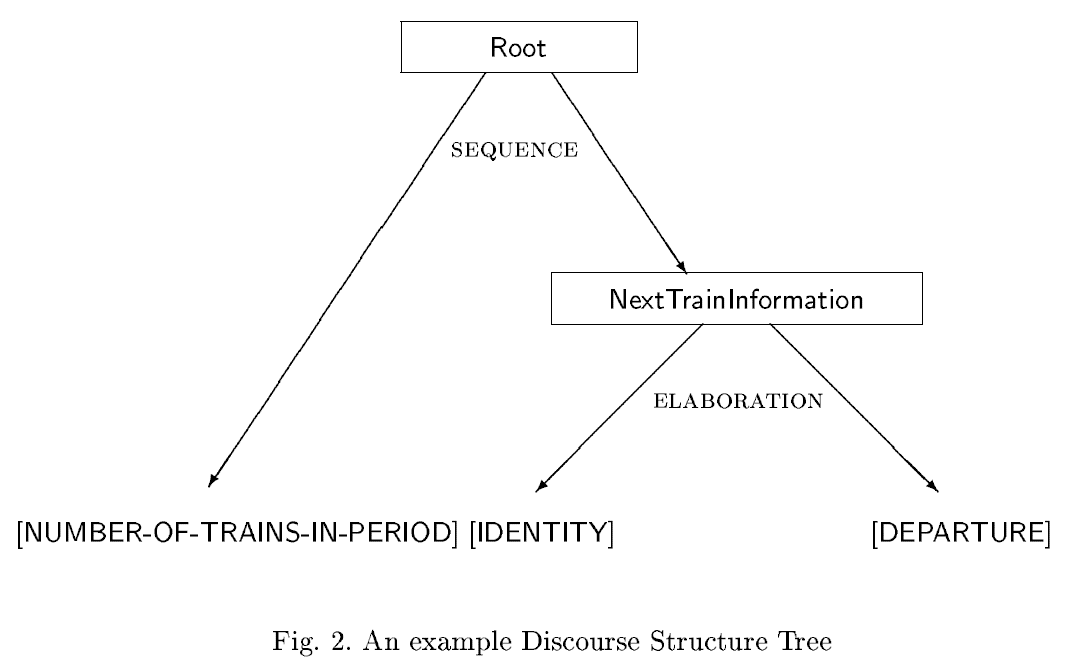
Discourse Planning
- Discourse Relations können helfen, Messages miteinander zu verknüpfen:

- Signalwörter für Discourse Relations: but, however, yet, therefore...
Schemata
- Die meisten Anwendungen für NLG brauchen nur eine übersichtliche Anzahl von Satzmustern.
- Diese Muster können anhand des Target Corpus und Expertenberatung im Vorhinein festgelegt werden.
- Ein Schema ist ein Plan dafür, wie Messages zusammengesetzt werden können.
Schemata

Interne Formate
Beispiel für einen in SPL formulierten Sentence Plan:
Sentence Aggregation
- Mehrere Messages pro Satz gruppieren, Variation einbauen
- Effekt: Deutlich höhere Lesbarkeit als Texte mit einer Message pro Satz
- Der Content selbst wird dadurch nicht verändert, aber wird ggf. einfacher zu erschließen
- Hilfen beim Erstellen der Regeln: Psycholinguistische Forschung über das Leseverhalten, Studien über das Leseverständnis, Expertenberatung
Sentence Aggregation

Lexicalization
- Die meisten Konzepte können durch mehr als eine einzige Vokabel ausgedrückt werden
- Je nach Kontext kann es vorteilhaft sein, für bestimmte Dinge ausschließlich einen Begriff zu verwenden...
- ... oder im Vokabular zu variieren, was wiederum zu besserer Lesbarkeit und "menschlicherem" Tonfall führt
Referring Expression Generation
- Ähnlich wie Lexikalisierung, aber mit Bezug auf spezifische Entitäten
- Aufgabe: Die Entitäten im Diskurs eindeutig identifizieren, u.a. auf Grundlage der vorherigen Sätze
- "The next train is the Caledonian Express. It leaves at..."
- Erste Vorstellung der Entität: z.B. mit Name, eindeutiger Identifizierung
- Pronomen im Textkörper: Rückbezug auf vorher erwähnte Identität (Stichwort Anapher)
- Definite Beschreibungen: Ausreichende Identifizierung, nicht genauer als nötig
Lexicalization und Referring Expression Generation

Linguistic Realization
- KNG-Kongruenz
- richtige Verbformen
- richtige Reihenfolge der Elemente im Satz
- Zeichensetzung
Möglichkeiten zur Linguistic Realization
- Grammatikbasierte Ansätze (Systemic-Functional Linguistics)
- Templates (nützlich bei geringer syntaktischer Variation)
- In jedem Fall: Unterspezifizierte "Textskelette", die mit den vorher ausgewählten Inhalten zusammengeführt werden
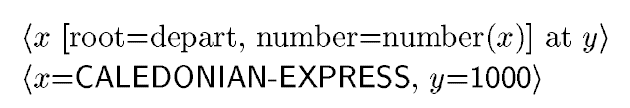
Generierung vs. Parsing
- Idee: NLG ist "wie Parsing, nur andersrum"
- Bidirektionale Grammatiken sollen in der Lage sein, beide Aufgaben zu ermöglichen
- Was haltet ihr von dieser Ansicht?
Jurafsky & Martin
To be useful in more complex environments, a generation system must be capable of: (1) producing an appropriate range of forms, and (2) choosing among those forms based on the intended meaning and the context. In this chapter, we will study the basic language generation techniques used to solve these problems, ignoring canned text and template-based mechanisms.
Anwendungsbezug
- Textgenerierungssysteme unterscheiden sich sehr stark, je nach Anwendungsbereich.
- Die linguistischen (grammatischen) Regeln bleiben innerhalb einer Sprache zwar größtenteils gleich...
- ... es kann aber dennoch Abweichungen geben, wenn ein Kontext z.B. abgekürzte Sätze oder nur Stichpunkte verlangt.
Generierung vs. Parsing
- Natural Language Understanding: "hypothesis management"
- Welche Informationen können aus einem vorliegenden Text auf welche Weise entnommen werden?
- NLG: Kaum Ambiguitäten, ausführlich spezifizierte Daten, wohlgeformter Input
- Hauptaufgabe hier: Auswahl der angemessensten Versprachlichung
Architektur von Textgenerierungssystemen
Surface Realization mit Systemic Grammars
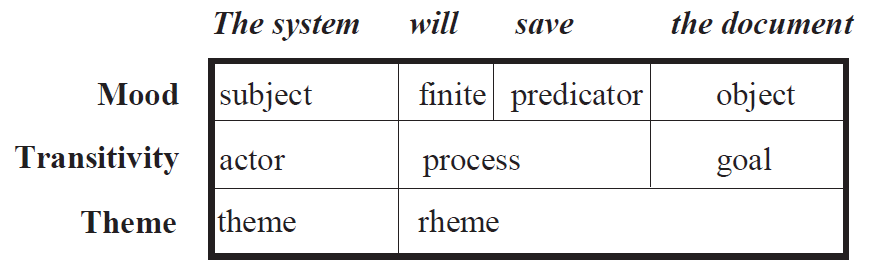
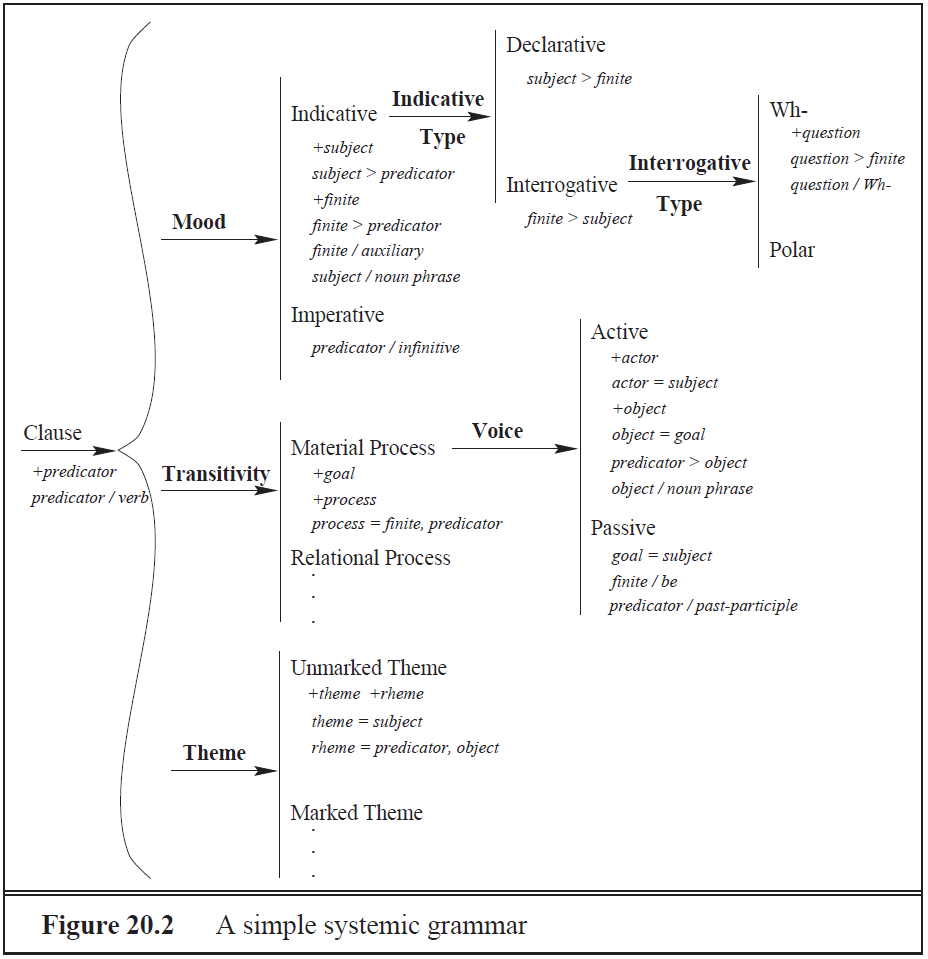
Surface Realization mit Systemic Grammars
Input, der versprachlicht werden soll:
Surface Realization mit Systemic Grammars
- Die Grammatik wird von oben nach unten und von links nach rechts durchlaufen, wobei die jeweils geforderten Entscheidungen getroffen werden.
- Dabei wird nach und nach die folgende Struktur aufgebaut:
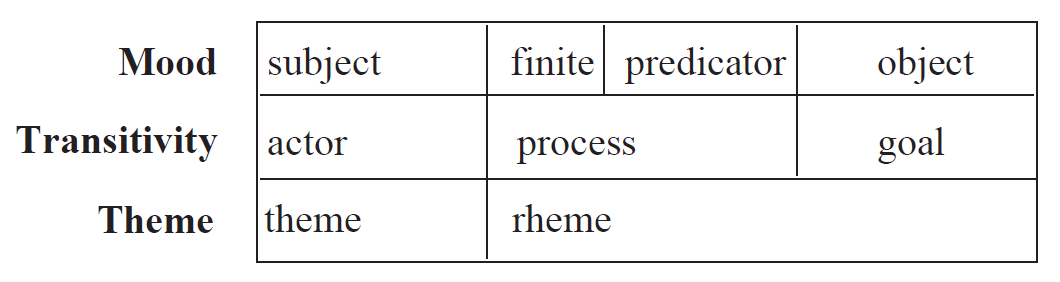
- Für jedes so entstandene Feld der Tabelle muss wieder die Grammatik konsultiert werden, um die entsprechenden Phrasen zu produzieren.
Surface Realization mit Functional Unification Grammars
- Grundidee: Die grammatischen Strukturen werden als Bäume oder Feature-Wert-Matrizen abgelegt.
- Jeder Input wird ebenfalls als Baum oder Feature-Wert-Matrix übergeben.
- Durch Unifizierung von Variablen wird eine Repräsentation der linguistischen Form erzeugt.
Grammatik
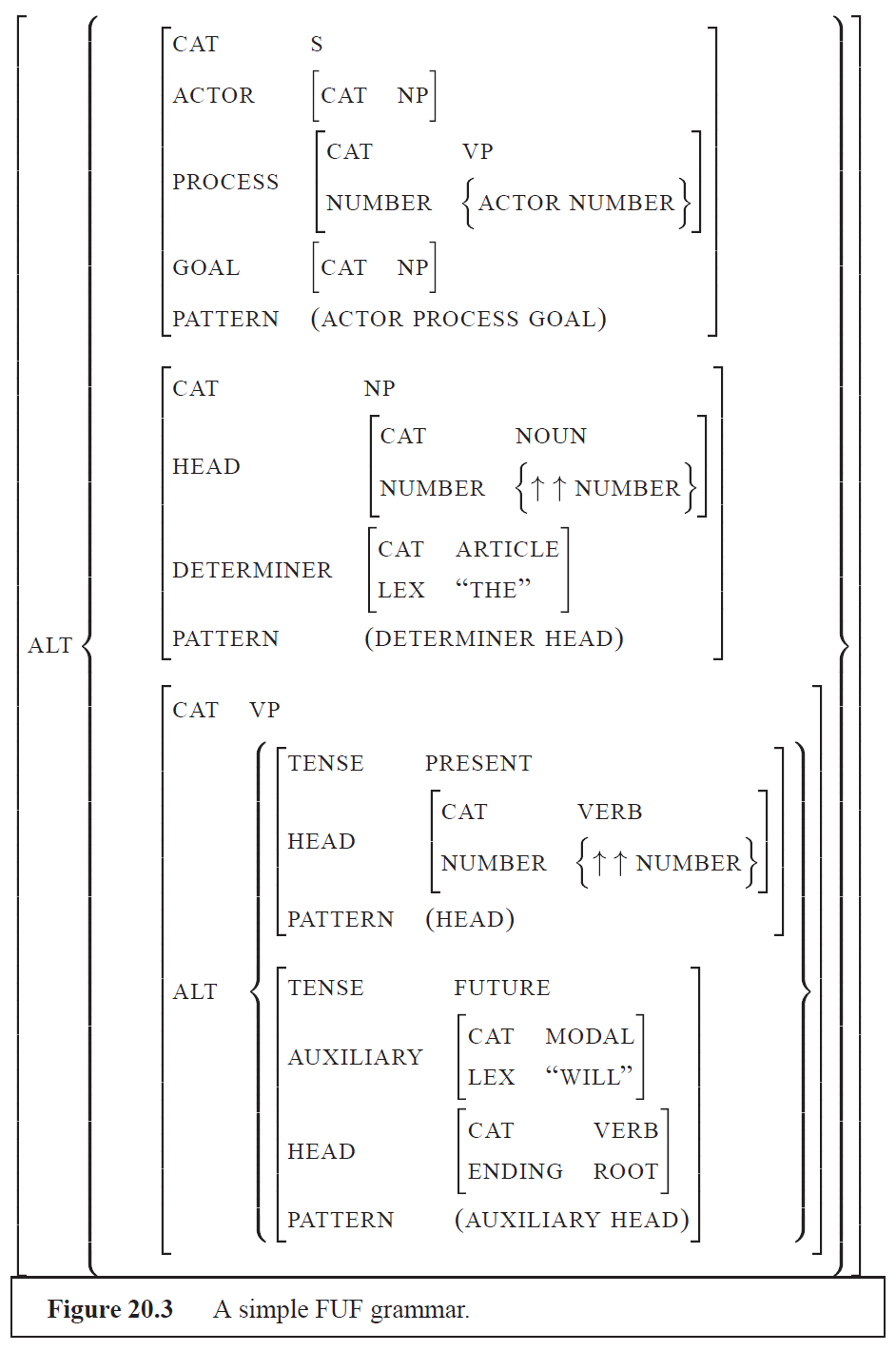
Surface Realization mit Systemic Grammars
Input, der versprachlicht werden soll: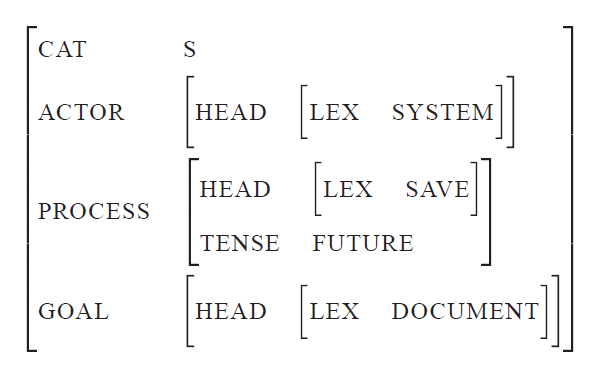
Ergebnis

Discourse Planning
Knowledge Base
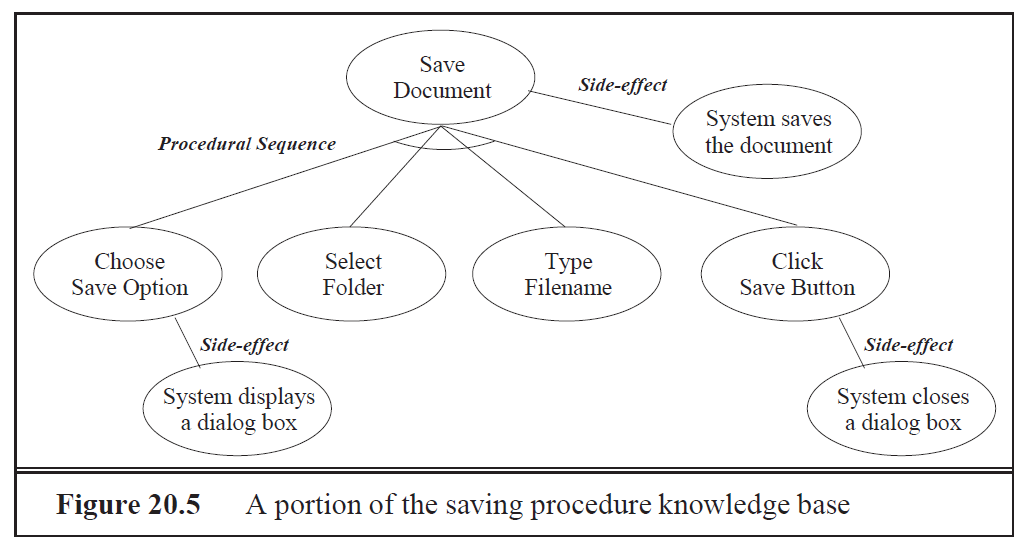
Schema zur Abbildung der Knowledge Base
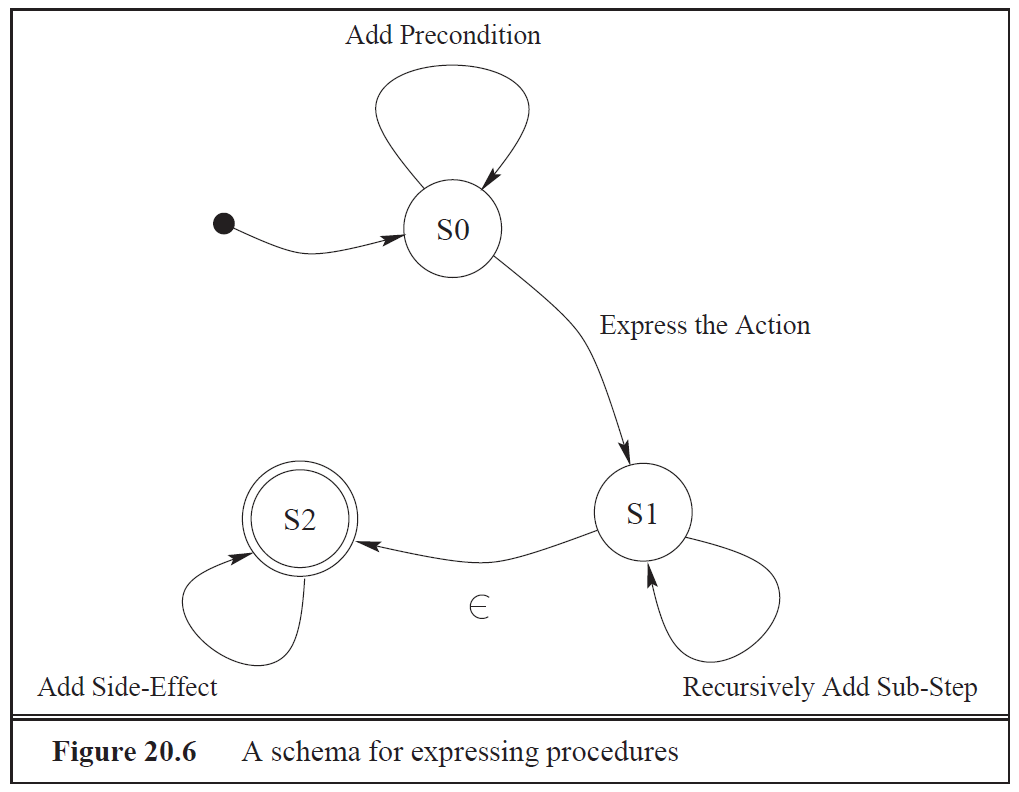
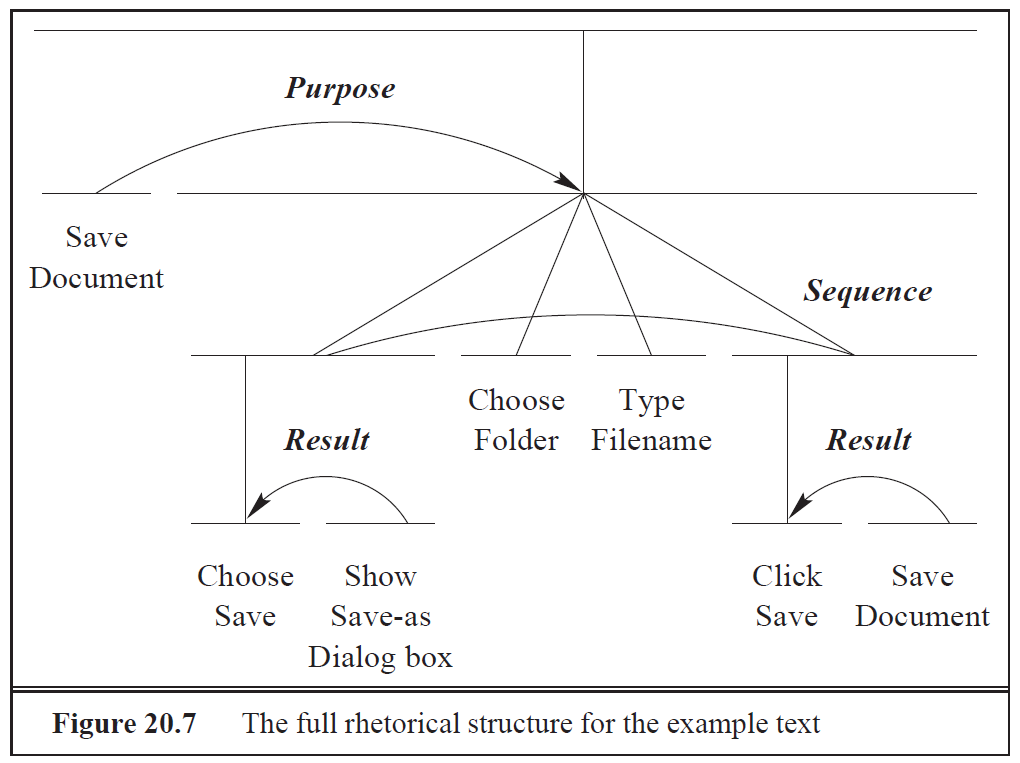
Rhetorical Relations
- "Klebstoff" zwischen Messages, z.B. Elaboration, Contrast, Condition, Purpose, Sequence, Result
- Die Relations sind binär und bestehen entweder aus einem nucleus und einem satellite oder aus zwei gleichwertigen nuclei.
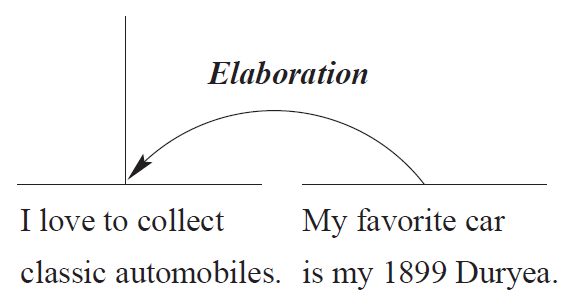
Rhetorical Relations
Die Relations können hierarchisch kombiniert werden: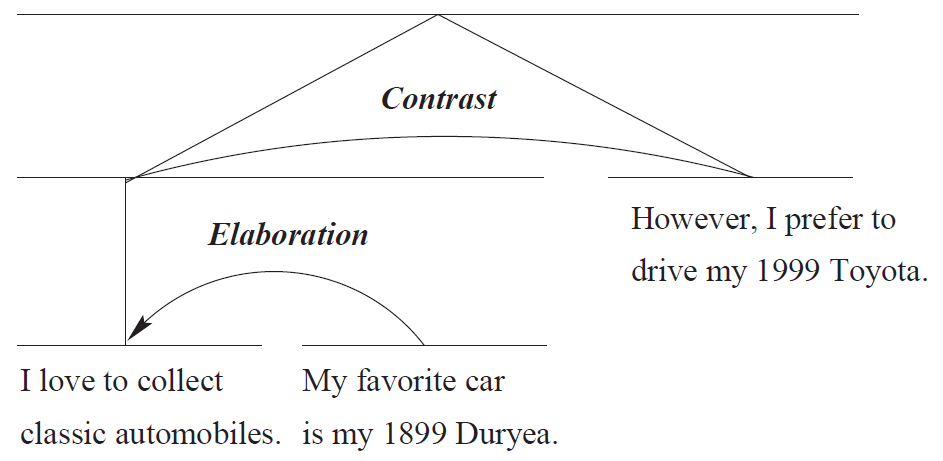
Rhetorical Relations im Beispiel
Evaluierung von NLG-Systemen
- Statistisches Vergleichen des Outputs mit dem Goldstandard des Target Corpus
- Problem: Target Corpus kann Abweichungen, Flüchtigkeitsfehler etc. enthalten
- Expertenbefragung nach Art eines Turing-Tests
- Effektivität des NLG-Systems: Experimente mit menschlichen Probanden
- Inhaltliche Fragen zu den generierten Texten
- Praktische Aufgaben zu den Texten
Natural Language Generation: Umsetzungsbeispiele
Choosing Words in Computer-Generated Weather Forecasts
One of the main challenges in automatically generating textual weather forecasts is choosing appropriate English words to communicate numeric weather data. A corpus-based analysis of how humans write forecasts showed that there were major differences in how individual writers performed this task, that is, in how they translated data into words. These differences included both different preferences between potential near-synonyms that could be used to express information, and also differences in the meanings that individual writers associated with specific words.
Weather Forecasts
- Zentrale Frage: Wie können nichtsprachliche Daten in Sprache übersetzt werden?
- Wie stellt man sicher, dass die Ergebnisse bei Menschen gut ankommen?
- Wie kann man Unterschiede im Idiolekt berücksichtigen?
Weather Forecasts: Menschliche Autoren
- Analyse eines Korpus aus Wetterberichten, die von Menschen formuliert wurden
- Starke Unterschiede bei den Präferenzen für Quasisynonyme, z.B. kalt/kühl
- Inkonsistentes Mapping zwischen Bedeutung und Versprachlichung, vor allem bei Zeitangaben ("mittags", "früher Nachmittag")
Weather Forecasts: Informationsvermittlung
- Im Rahmen von SumTime wurden drei Textgenerierungsprojekte durchgeführt:
- Zusammenfassung von Messungen aus Gasturbinen
- Zusammenfassung von Patientendaten einer Intensivstation
- Zusammenfassung meteorologischer Daten in Form von Wetterberichten
- Als das zweite Projekt evaluiert wurde, erklärten die Ärzte, dass sie graphisch aufbereitete Daten bevorzugen...
- ... trafen aber bei sprachlich aufbereiteten Daten bessere Entscheidungen
Weather Forecasts: Publikumsorientierung
- Die Autoren des Papers streben möglichst hohe Konsistenz und möglichst geringe Ambiguität an
- Wetterberichte dienen für unterschiedliche Leser/innen verschiedenen Zwecken:
- Pilot: Wind
- Landwirtschaft: Temperatur
- Allgemein: Nur die Aspekte der Daten sind relevant, die dem Nutzer beim Treffen von Entscheidungen helfen
Weather Forecasts: Ablauf der Generierung
- Document Planning: Auswahl der Daten, grobe Planung der Struktur (Orientierung an menschlichen Autoren)
- Microplanning: Lexikalisierung, Aggregierung, Referring Expressions Generation
- Surface Realisation: Endergebnis, fertiger Text (in dieser Anwendung in weatherese)
Weather Forecasts: Einige Ergebnisse

Weather Forecasts: Evaluation
Using Natural Language Generation in Automatic Route Description
In this paper we tackle the problem of generating natural route descriptions on the basis of input obtained from a commercially available way-finding system. Our framework and architecture incorporates the use of general principles drawn from the domain of natural language generation. Through examples we demonstrate that it is possible to bridge the gap between underlying data representations and natural sounding linguistic descriptions.
Route Description (Computer)
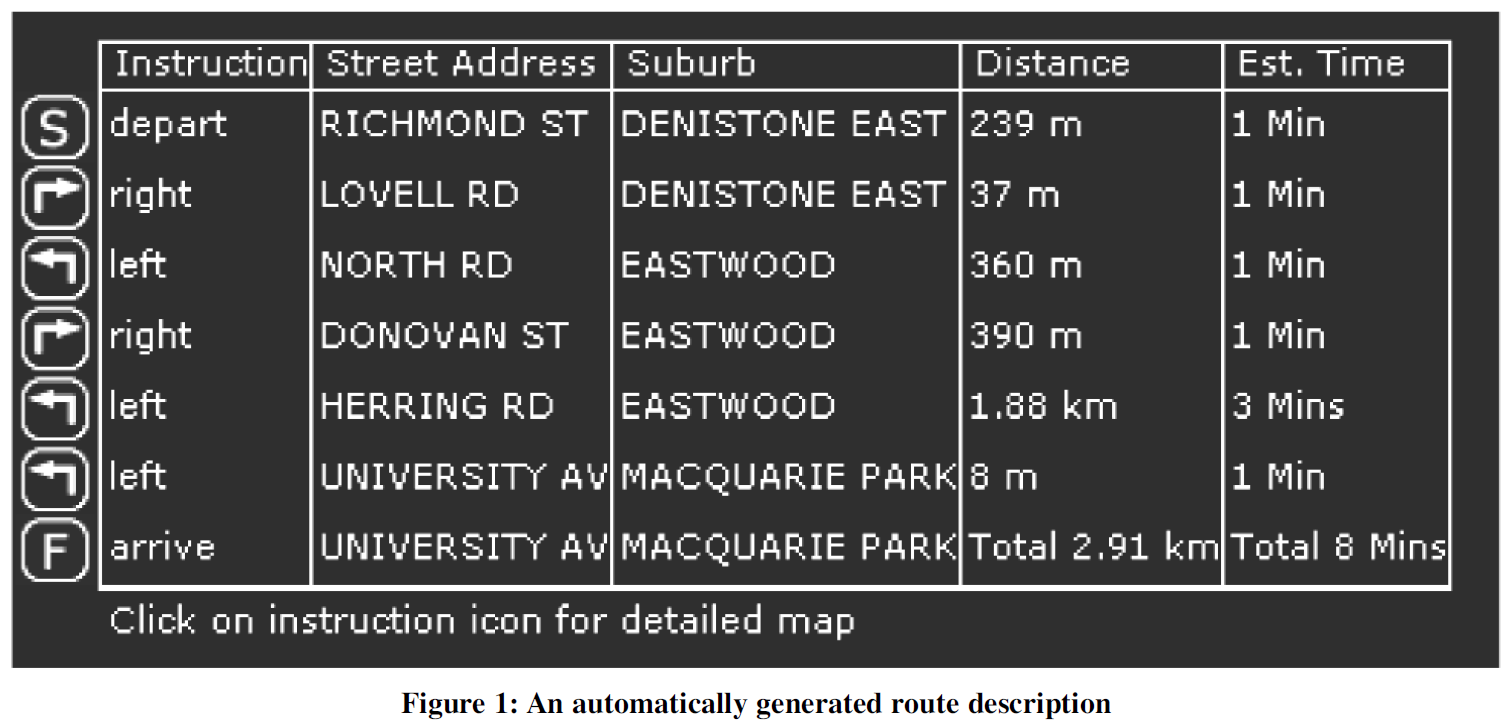
Route Description (Human)

Route Description
- Menschen lassen oft vermutlich unwichtige Schritte aus, die vom Computer aufgezählt werden
- Menschen verwenden in den Beschreibungen Orientierungspunkte, die leicht zu erkennen sind
- Computer geben die Route mit Entfernungs- oder Zeitangaben an, die für Menschen ggf. schwer abschätzbar sind
- Menschen bilden komplexe Sätze, um alle Zusammenhänge zu erklären, während Computer nur Ein-Satz-Beschreibungen erzeugen
Route Description: Strategien
- Discourse Structure: Bessere Strukturierung der Wegbeschreibung in nachvollziehbare Sinnabschnitte
- Aggregation techniques: Informationen zu flüssigen, nicht abgehackt wirkenden Sätzen zusammenfügen
- Referring expression generation techniques: Wegbeschreibungen User-orientiert gestalten, Orientierungspunkte verstärkt hervorheben
Route Description: Planung des Outputs
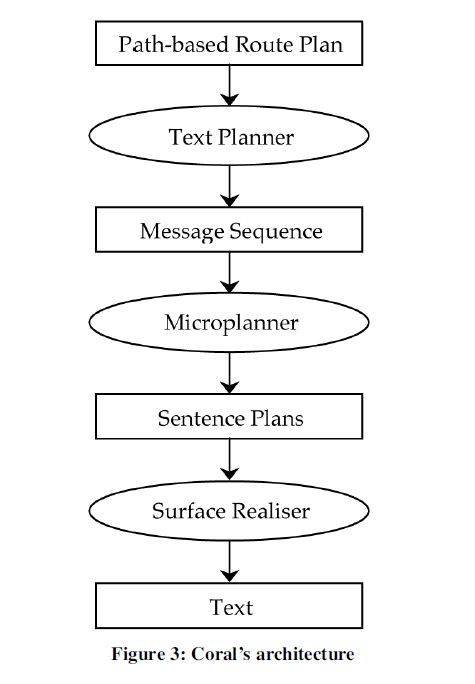
Route Planning Markup Language

Route Description: Results

Aktuellere Literatur
- Zhang, Y., & Clark, S. (2015). Discriminative syntax-based word ordering for text generation. Computational Linguistics, 41(3), 503-538.
- Garoufi, K., & Koller, A. (2014). Generation of effective referring expressions in situated context. Language, Cognition and Neuroscience, 29(8), 986-1001.
- Mairesse, F., & Young, S. (2014). Stochastic language generation in dialogue using factored language models. Computational Linguistics.
Aufgabe
- Lies einen der verlinkten Ausschnitte aus den aktuelleren Texten. Wie unterscheiden die beschriebenen Ansätze sich von denen, die in den älteren Texten geschildert werden? Welche Probleme treten bei den verwendeten Methoden auf? Wie gut oder schlecht sind die Ergebnisse? Für wie zuverlässig hältst du die Aussagen im Paper?
Und all das innerhalb von 4 Tagen????
- Twitterbots sind eine sehr kompakte Form der Textgenerierung.
- Wer möchte, kann natürlich ein beliebig komplexes Projekt bearbeiten...
- ... aber die meisten erfolgreichen Bots kommen mit einem "Mad Libs"-Approach (Templates) aus.
- Bot mit besonders komplexem Code: Tauntbot
- Für Bots mit besonders simplem (?) Code gibt es sogar ein Tool: Cheap Bots Done Quick
Cheap Bots Done Quick
- Einige Beispiel-Bots im CBDQ-Format:
- Im Grunde ist das CBDQ-Format eine etwas andere Notation von kontextfreien Grammatiken.
- Wir können das in Python auch mit wenig Aufwand umsetzen...
- ... und außerdem noch durch etwas Statistik interessanter machen (vgl. Wandering Monster Table).
- Außerdem sind wir viel flexibler in der Wahl des Vokabulars/der Datenquellen.
Community
- Am 11. und 12. März findet bei AEXEA in Stuttgart die dritte Computational Linguistics Unconference statt.
- Am 9. April findet der BotSummit, ein internationales Treffen von Bot-Enthusiasten, in London statt. Die Talks werden vermutlich livegestreamt.
- Im #botALLY-Slack-Channel werden technische, kreative und ethische Fragen über Bots und generative Kunst diskutiert.
- Im November läuft das Projekt National Novel Generation Month, dessen Ziel es ist, ein Buch aus 50.000 Wörtern zu generieren. Hier die Ergebnisse von 2014 und 2015.
Ausblick
- Morgen: Twitterbots, technische Grundlagen, Programmierübungen, erste Ideensammlung für eigene Projekte
- Mittwoch: Datenquellen, Planung der eigenen Projekte, Anfang der Umsetzung
- Donnerstag: Fertigstellung der Projekte (Präsenztermin gewünscht?), Vorbereitung der Präsentationen
- Freitag: Präsentation und Besprechung der Ergebnisse